Обробка деревовидних структур і уніфіковане AST
Дана стаття присвячена обробці AST за допомогою стратегій Visitor і Listener, перетворенню AST в уніфікований формат, спрощення AST, а також алгоритму зіставлення деревовидних структур.
Автор: Іван Кочуркін,
Розробник сигнатурного аналізатора коду,
Positive Technologies
Попередня стаття серії була присвячена теорії парсинга початкових кодів з використанням ANTLR і Roslyn. У ній було зазначено, що процес сигнатурного аналізу коду в нашому проекті PT Application Inspector розбитий на наступні етапи:
- парсинг в залежне від мови уявлення (abstract syntax tree, AST);
- перетворення AST в незалежний від мови уніфікований формат (Unified AST, UAST);
- безпосереднє зіставлення з шаблонами, описаними на DSL.
Дана стаття присвячена другому етапу, а саме: обробці AST за допомогою стратегій Visitor і Listener, перетворенню AST в уніфікований формат, спрощення AST, а також алгоритму зіставлення деревовидних структур.
обхід AST
Як відомо, парсер перетворює вихідний код в дерево розбору (в дерево, в якому прибрані всі незначущі токени), званому AST. Існують різні способи обробити таку дерево. Найпростіший - полягає в обробці дерева за допомогою рекурсивного обходу нащадків в глибину. Однак даний метод можна застосовувати тільки для зовсім простих випадків, в якому існує трохи типів вузлів і логіка обробки проста. В інших випадках, необхідно виносити логіку обробки кожного типу вузла в окремі методи. Це здійснюється за допомогою двох типових підходів (патернів проектування): Visitor і Listener.
Visitor і Listener
У Visitor для відвідування нащадків вузла необхідно вручну викликати методи обходу дочірніх вузлів. При цьому якщо батько має три нащадка, і викликати методи тільки для двох вузлів, то частина поддерева взагалі не буде оброблена. У Listener (Walker) ж методи відвідування всіх нащадків викликаються автоматично. У Listener існує метод, що викликається на початку відвідування вузла (enterNode) і метод, що викликається після відвідування вузла (exitNode). Ці методи також можна реалізувати за допомогою механізму подій. Методи Visitor, на відміну від Listener, можуть повертати об'єкти і навіть можуть бути типізований, тобто при оголошенні CSharpSyntaxVisitor кожен метод Visit, буде повертати об'єкт AstNode, який в нашому випадку є спільним предком для всіх інших вузлів уніфікованого AST.
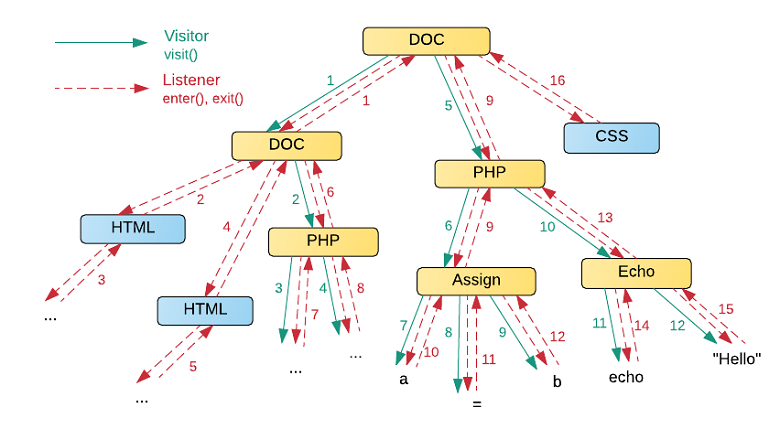
Таким чином, код перетворення дерева за допомогою Visitor виходить більш функціональним і лаконічним за рахунок того, що в ньому немає необхідності зберігати інформацію про відвідані вузлах. На малюнку нижче можна побачити, що, наприклад, при перетворенні мови PHP, непотрібні вузли HTML і CSS відсікаються. Порядок обходу позначений числами. Listener зазвичай використовується при агрегації даних (наприклад з файлів типу CSV), перетворенні одного коду в інший (JSON -> XML). Детальніше про це написано в The Definitive ANTLR 4 Reference .
Відмінності в Visitor в ANTLR і Roslyn
Реалізація Visitor і Listener може відрізнятися в бібліотеках. Наприклад, в таблиці нижче описані класи і методи Visitor і Listener в Roslyn і ANTLR.
ANTLR Roslyn Visitor AbstractParseTreeVisitor <Result> CSharpSyntaxVisitor <Result> Listener IParseTreeListener CSharpSyntaxWalker Default DefaultResult DefaultVisit (SyntaxNode node) Visit Visit (IParseTree tree) Visit (SyntaxNode node)
І ANTLR і Roslyn мають методи для повернення результату за замовчуванням (якщо метод Visitor для якоїсь синтаксичної конструкції не перевизначений), а також узагальнений метод Visit, який сам визначає, який спеціальний метод Visitor повинен викликатися.
У ANTLR візитор для кожного синтаксичного правила граматики генерується власний Visitor. Також існують спеціальні типи методів:
- VisitChild (IRuleNode node); використовується для реалізації обходу вузла за замовчуванням.
- VisitTerminal (IRuleNode node); використовується при обході термінальних вузлів, тобто токенов.
- VisitErrorNode (IErrorNode node); використовується при обході токенов, отриманих в результаті парсинга коду з лексичними або синтаксичними помилками. Наприклад, якщо в утвердженні пропущена крапка з комою в кінці, то парсер вставить такий токен і вкаже, що він є помилковим. Детальніше про помилки парсинга написано в попередній статті .
- AggregateResult (AstNode aggregate, AstNode nextResult); рідко використовуваний метод, призначений для агрегації результатів обходу нащадків.
- ShouldVisitNextChild (IRuleNode node, AstNode currentResult); рідко використовуваний метод, призначений для визначення того, чи потрібно обробляти наступного нащадка node в залежності від результату обходу вузла currentNode.
Roslyn візитор має спеціальні методи для кожної синтаксичної конструкції і узагальнений метод Visit для всіх вузлів. Однак методів для обходу "проміжних" конструкцій в ньому немає, на відміну від ANTLR. Наприклад, в Roslyn не існує методу для тверджень VisitStatement, а тільки існують спеціальні VisitDoStatement, VisitExpressionStatement, VisitForStatement і т.д. У качествеVisitStatement можна використовувати узагальнений Visit. Ще однією відмінністю є те, що методи обходу тривіальних (SyntaxTrivia) вузлів, тобто вузлів, які можна видалити без втрати інформації про код (прогалини, коментарі), викликаються поряд з методами обходу основних вузлів і токенов.
Недоліком ANTLR візитор є те, що назви згенерованих методів-Visitor безпосередньо залежать від стилю написання правил граматики, тому вони можуть не вписуватися в загальну стилістику коду. Наприклад, в sql-граматиках прийнято використовувати так званий Snake case, в якому для поділу слів використовуються символи підкреслення. Roslyn методи написані в стилістиці C #-коду. Незважаючи на відмінності, методи обробки деревовидних структур в Roslyn і ANTLR з новими версіями все більше і більше уніфікуються, що не може не радувати (в ANTLR версії 3 і нижче не було механізму Visitor і Listener).
Граматика і Visitor в ANTLR.
У ANTLR для правила
ifStatement
: If parenthesis statement elseIfStatement * elseStatement?
| If parenthesis ':' innerStatementList elseIfColonStatement * elseColonStatement? EndIf ';'
;
буде сформований метод VisitIfStatement (PHPParser.IfStatementContext context) в якому context матиме наступні поля:
- parenthesis - одиничний вузол;
- elseIfStatement * - масив вузлів. Якщо синтаксис відсутня, то довжина масиву дорівнює нулю;
- elseStatement? - опціональний вузол. Якщо синтаксис відсутня, то приймає значення null;
- If, EndIf - термінальні вузли, починаються з великої літери;
- ':', ';' - термінальні вузли, не містяться в context (доступні тільки через GetChild ()).
Варто відзначити, що чим менше правил існує в граматиці, тим легше і швидше писати Visitor. Однак повторюється синтаксис також потрібно виносити в окремі правила.
Альтернативні і елементні мітки в ANTLR
Часто виникають ситуації, в яких правило має кілька альтернатив і було б логічніше обробляти ці альтернативи в окремих методах. На щастя, в ANTLR 4 для це існують спеціальниеальтернатівние мітки, які починаються з символу # і додаються після кожної альтернативи правила. При генерації коду парсера, для кожної мітки генерується окремий метод-Visitor, що дозволяє уникнути великої кількості коду в разі, якщо правило має багато альтернатив. Варто відзначити, що позначатися повинні або все альтернативи, або жодної. Також для позначення терміналу, що приймає безліч значень, можна використовувати елементні мітки (rule element label):
expression: op = ( '+' | '-' | '++' | '-') expression #UnaryOperatorExpression
| expression op = ( '*' | '/' | '%') expression #MultiplyExpression
| expression op = ( '+' | '-') expression #AdditionExpression
| expression op = '&&' expression #LogicalAndExpression
| expression op = '?' expression op2 = ':' expression #TernaryOperatorExpression
;
Для цього правила ANTLR згенерує візитор VisitExpression, VisitUnaryOperatorExpression, VisitMultiplyExpression тощо. У кожному візитор буде існувати масив expression, що складається з 1 або 2 елементів, а також буквальний op. Завдяки мітках, код візитор буде чистішим і лаконічним:
public override AstNode VisitUnaryOperatorExpression (TestParser.UnaryOperatorExpressionContext context)
{
var op = new MyUnaryOperator (context.op (). GetText ());
var expr = (Expression) VisitExpression (context.expression (0));
return new MyUnaryExpression (op, expr);
}
public override AstNode VisitMultiplyExpression (TestParser.MultiplyExpressionContext context)
{
var left = (Expression) VisitExpression (context.expression (0));
var op = new MyBinaryOpeartor (context.op (). GetText ());
var right = (Expression) VisitExpression (context.expression (1));
return new MyBinaryExpression (left, op, right);
}
public override AstNode VisitTernaryOperatorExpression (TestParser.TernaryOperatorExpressionContext context)
{
var first = (Expression) VisitExpression (context.expression (0));
var second = (Expression) VisitExpression (context.expression (1));
var third = (Expression) VisitExpression (context.expression (2));
return new MyTernaryExpression (first, second, third);
}
...
Без альтернативні міток, обробка Expression перебувала б в одному методі і код виглядав так:
public override AstNode VisitExpression (TestParser.ExpressionContext context)
{
Expression expr, expr2, expr3;
if (context.ChildCount == 2) // Unary
{
var op = new MyUnaryOperator (context.GetChild (0) .GetText ());
expr = (Expression) VisitExpression (context.expression (0));
return new MyUnaryExpression (op, expr);
}
else if (context.ChildCount == 3) // Binary
{
expr = (Expression) VisitExpression (context.expression (0));
var binaryOp = new MyBinaryOpeartor (context.GetChild (0) .GetText ());
expr2 = (Expression) VisitExpression (context.expression (1));
return new MyBinaryExpression (expr, binaryOp, expr2);
...
}
else // Ternary
{
var first = (Expression) VisitExpression (context.expression (0));
var second = (Expression) VisitExpression (context.expression (1));
var third = (Expression) VisitExpression (context.expression (2));
return new MyTernaryExpression (first, second, third);
}
}
Варто зазначити, що альтернативні мітки існують не тільки в ANTLR, а й інших засобах для опису граматик. Наприклад, в Nitra мітка зі знаком присвоювання ставиться зліва від альтернативи, на відміну від ANTLR:
syntax Expression {| IntegerLiteral | BooleanLiteral | NullLiteral = "null"; | Parenthesized = "(" Expression ")"; | Cast1 = "("! Expression AnyType ")" Expression; | ThisAccess = "this"; | BaseAccessMember = "base" "." QualifiedName; | RegularStringLiteral;
Типи вузлів уніфікованого AST
При розробці структури уніфікованого AST і типів вузлів, ми керувалися структурою AST з проекту NRefactory з огляду на те, що вона є нам досить простий, а отримання достовірного дерева (fidelity, оборотне в вихідний код з точністю до символу) не було потрібно. Будь-вузол є спадкоємцем AstNode і має власний тип NodeType, який також використовується на етапі зіставлення з шаблонами і при десеріалізациі з JSON. Структура вузлів виглядала приблизно так:
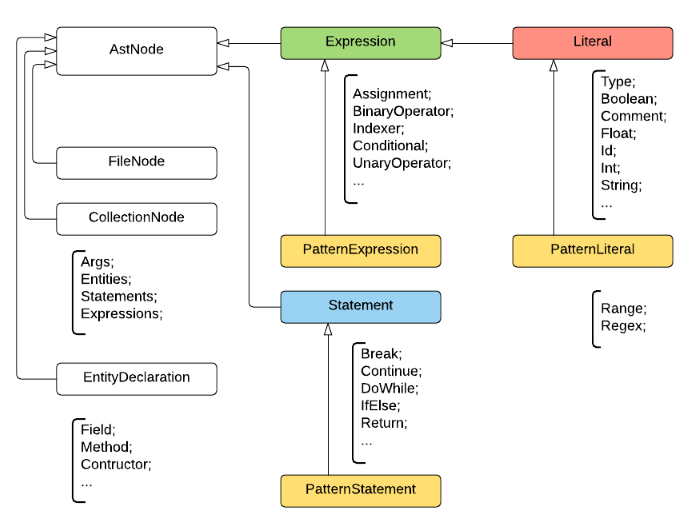
Крім типу, кожен вузол має властивість, що зберігає розташування в коді (TextSpan), яке використовується для його відображення в вихідний код при зіставленні з шаблоном. Нетермінальний вузол зберігає список дочірніх вузлів, а термінальний - числове, строкове або інше примітивне значення.
Для того, щоб порівняти вузли AST різних мов, була складена таблиця, в якій рядками був синтаксис певних вузлів, а стовпцями - їх реалізація в мовах C #, Java, PHP, що виглядало наступним чином:
Node Args C # Java PHP MCA MDA While cond: Expression; stmt: Statement while (cond) stmt while (cond) stmt while (cond) stmt While (cond, stmt) While (cond, stmt) BinaryOp l, r: Expression; op: Literal l op rl op rl op r BinaryOp (l, op, r) BinaryOp (l, op, r) ... ... ... ... ... ... ... Checked checked: Expression checked (checked) - - checked Checked (checked) NullConditional a: Expression, b: Literal a? .b - - a! = null? ab: null a? .b
У цій таблиці:
- Expression; вираз, має значення, що повертається.
- Statement; твердження (інструкція), не має значення, що повертається.
- Literal; термінальний вузол.
- Most Common Ast (MCA) найбільш уніфіковане AST. Даний вузол будується, якщо всі три мови містять в собі тип такого або подібного вузла (наприклад, IfStatement, AssignmentExpression);
- Most Detail Ast (MDA) найбільш деталізоване AST. Даний вузол будується, якщо хоча б одна мова містить в собі такий тип вузла (наприклад, FixedStatenemt fixed (a) {} для C #). Дані вузли більш актуальні для SQL подібних мов, через те що останні декларативні мови і між T-SQL і C # різниця набагато більше, ніж, наприклад, між PHP і C #.
Крім вузлів, представлених на малюнку (і "вузлів-патернів", які описані в наступному розділі), існують ще штучні вузли для того, щоб все ж побудувати вузол Most Common Ast, "втративши" при цьому якомога менше синтаксису. Такими вузлами є:
- MultichildExpression; має тип Expression, але при цьому містить в собі колекцію інших Expression;
- WrapperExpression; має тип Expression, але при цьому містить в собі будь-який AstNode;
- WrapperStatement; має тип Statement, але при цьому містить в собі будь-який AstNode.
В імперативних мовах програмування основними конструкціями є вираження Expression і затвердження Statement. Перші мають значення, що повертається, другі ж використовуються для здійснення будь-яких операцій. Тому в нашому модулі ми також сконцентровано здебільшого на них. Вони є базовими "цеглинками" для реалізації CFG та інших уявлень вихідного коду, необхідних для реалізації taint-аналізу в майбутньому. Варто додати, що знання про синтаксичному цукрі, дженериках та інших специфічних для конкретної мови речей пошуку вразливостей в коді не потрібно. Тому синтаксичний цукор можна розкривати в стандартні конструкції, а інформацію про специфічних речах взагалі видаляти.
Патерн-вузлами є штучні вузли, що представляють власні шаблони. Наприклад, в якості патернів-литералов використовуються діапазони чисел, регулярні вирази.
тестування конвертерів
Для аналізатора коду пріоритетним завданням є тестування всього коду, а не окремих його частин. Для вирішення цього завдання було вирішено перевантажити методи-візитор для всіх типів вузлів. При цьому, якщо візитор не використовується, то він генерує виняток new ShouldNotBeVisitedException (context). Такий підхід спрощує розробку, оскільки IntelliSense враховує, які методи перевантажені, а які - ні, тому легко визначити, які методи візитор вже були реалізовані.
Також ми маємо деякі міркування на тему того, як поліпшити тестування покриття всього коду. Кожен вузол уніфікованого AST зберігає в собі координати відповідного йому вихідного коду. При цьому всі термінали пов'язані з лексемами, тобто певними послідовностями символів. Так як всі лексеми по можливості необхідно обробити, то загальний коефіцієнт покриття можна виразити наступною формулою, в якій uterms - термінали уніфікованого AST, а terms - термінали звичайного Roslyn або ANTLR AST:

Дана метрика висловлює покриття коду за допомогою одного коефіцієнта, який повинен прагнути до одиниці. Звичайно, оцінка по цьому коефіцієнту є приблизною, однак його можна використовувати при рефакторінгу і поліпшенні коду візитор. Для більш достовірного аналізу також можна використовувати графічне представлення покритих терміналів.
спрощення AST
Після перетворення звичайного AST в UAST, останнім потрібно спростити. Найбільш простий і корисною оптимізацією є згортка констант (Constant folding). Наприклад, існує окремий клас нестачі коду, пов'язаний з установкою занадто великого часу життя для cookie: cookie.setMaxAge (2147483647); Аргумент в дужках може бути записаний як одним числом, наприклад 86400, так і якимось арифметичним виразом, наприклад 60 * 60 * 24. Інший приклад пов'язаний з конкатенацией рядків при пошуку SQL-ін'єкцій та інших вразливостей.
Для реалізації цього завдання був реалізований власний інтерфейс і сам Visitor тільки вже для UAST. Так як спрощення AST просто зменшує кількість вузлів дерева, то Visitor був типізованим, які приймають і повертає один і той же тип. Завдяки підтримці рефлексії в .NET, вийшло реалізувати такий Visitor з невеликою кількістю коду. Так як кожен вузол містить в собі інші вузли або термінальні примітивні значення, то за допомогою рефлексії можливо витягти всі члени певного вузла і обробити їх, викликаючи інші візитор рекурсивно.
Алгоритм зіставлення AST і шаблонів
При обході уніфікованого AST кожен шаблон "намагається" наложиться на шматочок AST поточного вузла. На початку порівнюється тип вузла, а потім, в залежності від типу, проводяться наступні операції:
- Рекурсивне порівняння нащадків.
- Порівняння простих літеральних типів (ідентифікатор, рядки, числа).
- Порівняння розширених літеральних типів (регулярні вирази, діапазони). Коментарі входять в цю групу.
- Порівняння складних розширені типів (вираження, послідовність Statement).
В основі даного алгоритму лежать прості принципи, що дозволяють досягти високої продуктивності при порівняно невеликій кількості реалізує їх коду. Останнє досягається за рахунок того, що метод CompareTo для порівняння вузлів реалізований для базового класу, терміналів і невеликого числа інших вузлів. Більш просунуті алгоритми зіставлення для поліпшення продуктивності, засновані на кінцевих автоматах, реалізовувати поки не було потрібно. Однак даний алгоритм проблематично (або навіть неможливо) використовувати для більш просунутого аналізу, наприклад, що враховує зв'язку між Statement.
висновок
У даній статті ми розглянули патерни Visitor і Listener для обробки дерев, а також розповіли про структуру уніфікованого AST. У наступних статтях ми розповімо:
- про підходам до зберігання шаблонів (Hardcoded, Json, DSL);
- розробці та використанні DSL для опису шаблонів;
- прикладах реальних шаблонів і їх пошуку у відкритих проектах;
- побудові CFG, DFG і taint-аналізі.
Checked checked: Expression checked (checked) - - checked Checked (checked) NullConditional a: Expression, b: Literal a?
Null?
Ab: null a?