Archive.org гордо і по праву називає себе «Архівом інтернету», і з далекого 1996 року парсит всю мережу з метою архівації та структурування даних. Цей сайт прямо або побічно може принести користь і нам. За даними Вікіпедії, на жовтень 2012 року, Архів містив дані про більш ніж 85 мільярдів сторінок, а загальний обсяг всіх архівуються даних перевищує 10 петабайт. Тут зберігається історія Інтернету в цілому і інтернет - бізнесу зокрема.
Archive.org гордо і по праву називає себе «Архівом інтернету», і з далекого 1996 року парсит всю мережу з метою архівації та структурування даних. Цей сайт прямо або побічно може принести користь і нам. За даними Вікіпедії, на жовтень 2012 року, Архів містив дані про більш ніж 85 мільярдів сторінок, а загальний обсяг всіх архівуються даних перевищує 10 петабайт. Тут зберігається історія Інтернету в цілому і інтернет - бізнесу зокрема.
Завдяки своїй старій історії та суспільно-соціальної діяльності Archive.org є одним з найбільш трастових сайтів інтернету. Про це можна судити за деякими показниками:
1. Вік сайту - майже 20 років (Registered On - December 14, 1995).
2. Google PR - 8 (Яндекс ТИЦ - 5200).
3. Велика кількість проіндексованих сторінок (~ 70 мільйонів).
4. Даний ресурс входить в 250 найбільших відвідують сайтів світу (згідно з даними Alexa.com).
Archive.org може стати корисним для кожного веб-майстра, якщо навчитися його використовувати в своїх цілях. Виходячи з усього написаного, можна зробити висновок, що Архів досить трастова майданчик для отримання лінків і створення доров. Також її можна використовувати за своїм основним напрямку, адже це величезний ресурс для отримання різного контенту.
Почнемо з самої цікавою та актуальною на сьогоднішній день теми - створення доров на сайті Archive.org. В Google ви без проблем знайдете багато прикладів класичних «профільних» доров на Archive .org по різним НЧ ключовим фарма - словами (для прикладу запит Buy Tadalafil Prescription Supplement Cost - перевірка по aol.com):
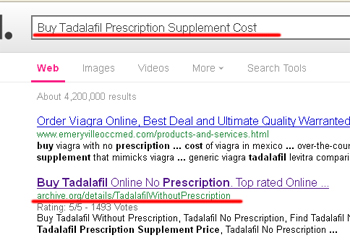
Конкретний дор використовує картіночний фид від PPC, але рекомендується робити красиві перенаправлення на свої фарма шопи. Розглянемо в загальних рисах процедуру створення дора. Для початку потрібно створити обліковий запис. Для цього слід перейти за посиланням https://archive.org/account/login.createaccount.php і заповнити всі поля:
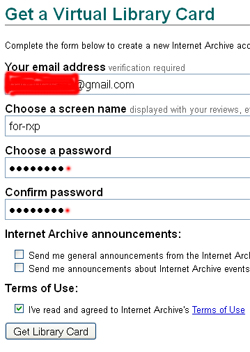
«Screen name» особливої ролі не грає, url майбутнього дора ви будете формувати самостійно. Email потрібно вказувати реальний, а реєстрацію аккаунта необхідно підтвердити. Проходять варіації в адресі Gmail (для вашого ящика [email protected], ви можете використовувати безмежну кількість варіацій, додаючи раномние символи зі знаком +: [email protected], [email protected], і вся пошта буде приходить в ваш ящик). Багато сервісів не приймають такий формат, змушуючи реєструвати багато нових скриньок. Але Archive.org поки не ввів додатковий захист.
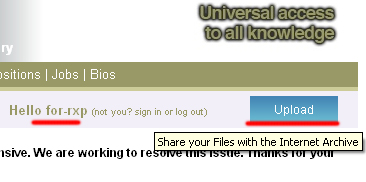
Для того, щоб створити дор за адресою http://archive.org/details/DOR необхідно залити будь-якої файл і в його опис вже вставити все, що вам необхідно. Після логіна ви відразу побачите синю кнопку «Upload» в правому кутку і, перейшовши по ній, форму завантаження:
Заливати можна як html з тим же Дором (але він не проиндексируется), так і просто будь-якої PDF на тему здоров'я. Вибираємо файл, натискаємо завантажити і потрапляємо в редактор:
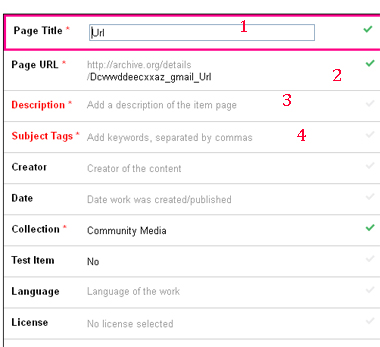
Основні моменти:
1. Page title - тайтл сторінки і майбутнього дора. Заповнюється згідно цілям.
2. Page url - частина адреси дора після / details /
3. Description - сам контент дора. Картинка для входу, КЕІ, текст і т.д.
4. Subject Tags - не дуже важливо, але допомагає для того, щоб дор був в пошуку по Архіву, що гарантує більш швидкий індекс.
В результаті чого отримуємо такий приклад - https://archive.org/details/rxpssssssz. У деяких випадках редактор може видалити посилання, але є можливість вставити її назад, натиснувши на Edit items (щоб не удаляло, пишіть спочатку в форматі a href = http: //google.com - тобто без лапок після =).
Кожен сам може підібрати необхідну схему створення і заливки доров. Додавайте текст, КЕІ та експерементіруйте з оформленням. На сторінці https://archive.org/details/opensource_media виводяться останні оновлення та комментарі (дуже повільно і незрозуміло), але на всяких випадок, щоб прискорити індексацію, напишіть собі 1-2 огляду, так ви потрапите в Recently Reviewed Items.
Ці ж огляди (Reviews) допоможуть отримати зірочки в сниппета Googla, що підвищить увагу у видачі до дору:
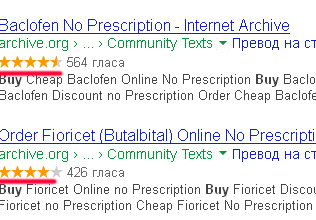
Що далі робити з дорамі ви знаєте. Аналогічно можна використовувати дані профілю для отримання посилальної маси. Правда скрізь буде Nofollow, про корисність якого ведуться постійні суперечки. Але посилання з настільки трастового ресурсу ніколи не завадить.
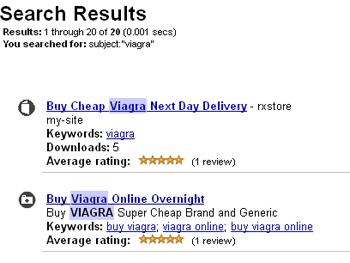
Якщо ви все ж вирішите її отримати, залийте який-небудь PDF файл зі звітом про останню конференції з лікування імпотенції собі на сайт. Такий же залийте в archive.org, а в описі джерела вкажіть, що ви знайшли його саме на своєму сайті. Це забезпечить практично довічне заслання. За діяльністю «колег по цеху» ви можете спостерігати завдяки внутрішньому пошуку. http://archive.org/search.php?query=subject%3A%22viagra%22:
Перейдемо до наступного сервісу від Archive.org, а саме - Web.Archive або WayBack Machine. Пошукові роботи даного сервісу обходять сайти і архівують їх на своїх серверах, створюючи копії для історії. Природно, що сайти досить часто перестають існувати, і копії в web архіві залишаються єдиним нагадуванням про них.
Дані сайти можна відновлювати і використовувати для своїх потреб. Можна використовувати їх як сателіти, як майданчика для посилань на свої ресурси або продаж, можна монетизувати за допомогою Adsense або партнерських програм. Для початку необхідно визначиться з тим, який саме сайт відновлювати. Це досить складне питання і існують кілька основних варіантів його рішення:
1. Пошук інформації на тематичних майданчиках з продажу доменів. Перехоплювачі часто продають звільнені домени із зазначенням того, є чи ні копія сайту в Web.Archive. Ви можете як купити домен і відновити колишній сайт, так і просто дізнатися, який сайт можна відновити на новому домені, загнавши його в індекс швидше, ніж це зробить потенційний покупець домену. Основний російськомовної майданчиком для покупки / продажу доменів є - доменфорум, дивіться також і на тематичних форумах для вебмайстрів.
2. Збір даних про звільнилися доменах самостійно.
3. Купівля доменів на аукціонах або просто використання інформації з них. Детально описано в хорошій статті https://www.rxpblog.com/work-with-auctions-buying-trusted-domains тут.
Ну і звичайно, якщо ви щільно працює в будь-якої теми, ви прекрасно знаєте своїх конкурентів, їх сателіти і інші місця, які в разі краху можна відновити для своїх цілей. Результати наявності в Архіві доступні за адресою http://web.archive.org/web/*/http://rxpblog.com:
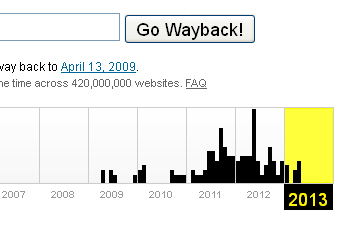
Після того як ми визначилися ЩО відновлювати, знадобляться інструменти для цього. Коли домен і його наявність в Веб.Архіве є відомими факторами, можна відразу приступати до відновлення. Але в разі, якщо ви використовуєте списки віддалених доменів, спочатку необхідно перевірити чи є історія для них в Архіві. Отримати списки таких доменів можна різними способами: існує величезна кількість online сервісів для deleted domains, як платних, так і безкоштовних, чокерів і програм.
Розглянемо приклад, як це робити за допомогою «Определяйкі» (офіційний сайт програми - http://netpeak.ua/soft/opredelyayka/). Після установки і запуску вам запропонують список опцій, за якими вона буде перевіряти домени:
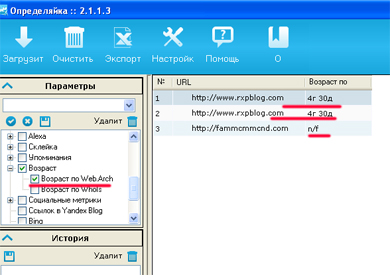
Відзначаємо чекбокс - Вік по Web.Archive, натискаємо кнопку «Завантажити», і якщо у сайту є історія в архіві, ви отримаєте його вік там, якщо немає - значення n / f. Потім робите експорт в файл Exel, сортуєте і вибираєте необхідні для роботи дані.
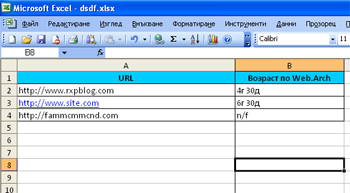
Тепер є список вільних доменів, які можуть бути перехоплені кіберсквотерами. Але це не страшно, адже в 90% випадків, якщо не більше, ці люди вішають домени на парковку або сторінку продажу, абсолютно не цікавлячись контентом з минулого життя сайтів з існуючою історією в Архіві.
Для парсинга результатів Архіву та їх локального збереження існує багато різного софту, і вибір залежить виключно від вас. Пошук потрібно робити по терміну - Web Archive Downloader / graber / parser. Розглянемо процес роботи на прикладі досить дешевого варіанта - Web Archive Downloader. Качаємо, купуємо ключ і запускаємо (без ключа можна зберігати до 20 сторінок з сайту). Вибираєте року, які цікавлять:
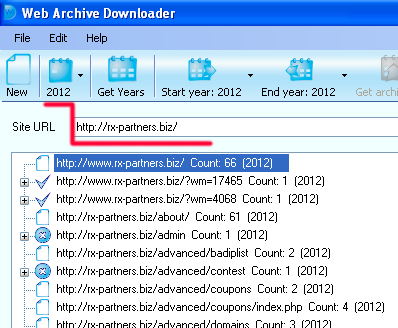
Вставляєте URL і натискаєте Get Url List:
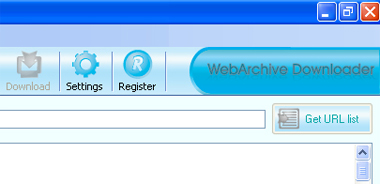
Через N хвилин завантажиться список доступних сторінок. Після цього натискаєте «Download» і почнеться завантаження сайту на ваш хард-диск. Далі сайт доведеться привести до товарного вигляду: поміняти шляху, поправити картинки і т.д., якщо автоматично цього зробити не вдалося. Звичайно, ви можете зробити те ж саме різними програмами з категорії Offline Explorer або знайти більш вдале ПО. Крім вилучення сайту можна і просто брати текстовий контент для подальшого застосування. Статті є унікальними для пошукових систем і їх можна сміливо використовувати для наповнення своїх сайтів і сателітів.
Як же ще можна застосувати архів сайту в роботі? Archive.org - це величезний архів текстової та медіа інформації. Наприклад, можна парсити книги, статті та інший текстовий матеріал для подальшої обробки та генерації в дорвейний технологіях або сплоги. Вбиваєте в пошук, наприклад, health і отримуєте список публікацій про здоров'я:
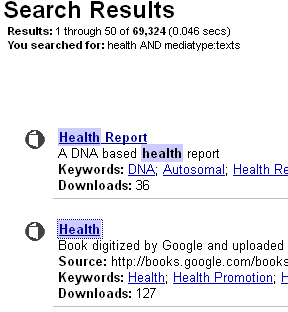
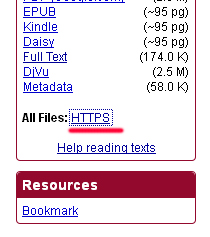
Практично у кожного результату будуть варіанти в .txt файлі, які легко зберігати і парсити для подальшого використання. Щоб дістатися до файлу в цьому форматі, необхідно натиснути на HTTPS лінк навпроти All files &.
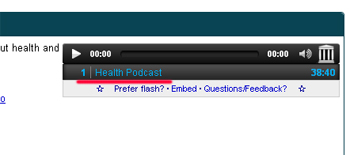
Крім текстової інформації даний ресурс складує і різні аудіо і відео записи, які теж можуть стати в нагоді для деяких блогів і сайтів. Якщо вбити в пошук запит health AND mediatype: audio, можна отримати подкасти та різні записи з радіостанцій на тему здоров'я.
Або health AND mediatype: movies і отримати ролики на тему здоров'я. Правильне їх використання може сильно підвищити поведінкові фактори на ваших ресурсах.
От і все. Сподіваюся, що кожен з вас по-новому відкриє для себе цей чудовий сайт, а дана стаття хоч трохи допоможе в нашій нелегкій справі. 🙂
Автор статті: LoNduk.
Php?Як же ще можна застосувати архів сайту в роботі?